Em operação
01
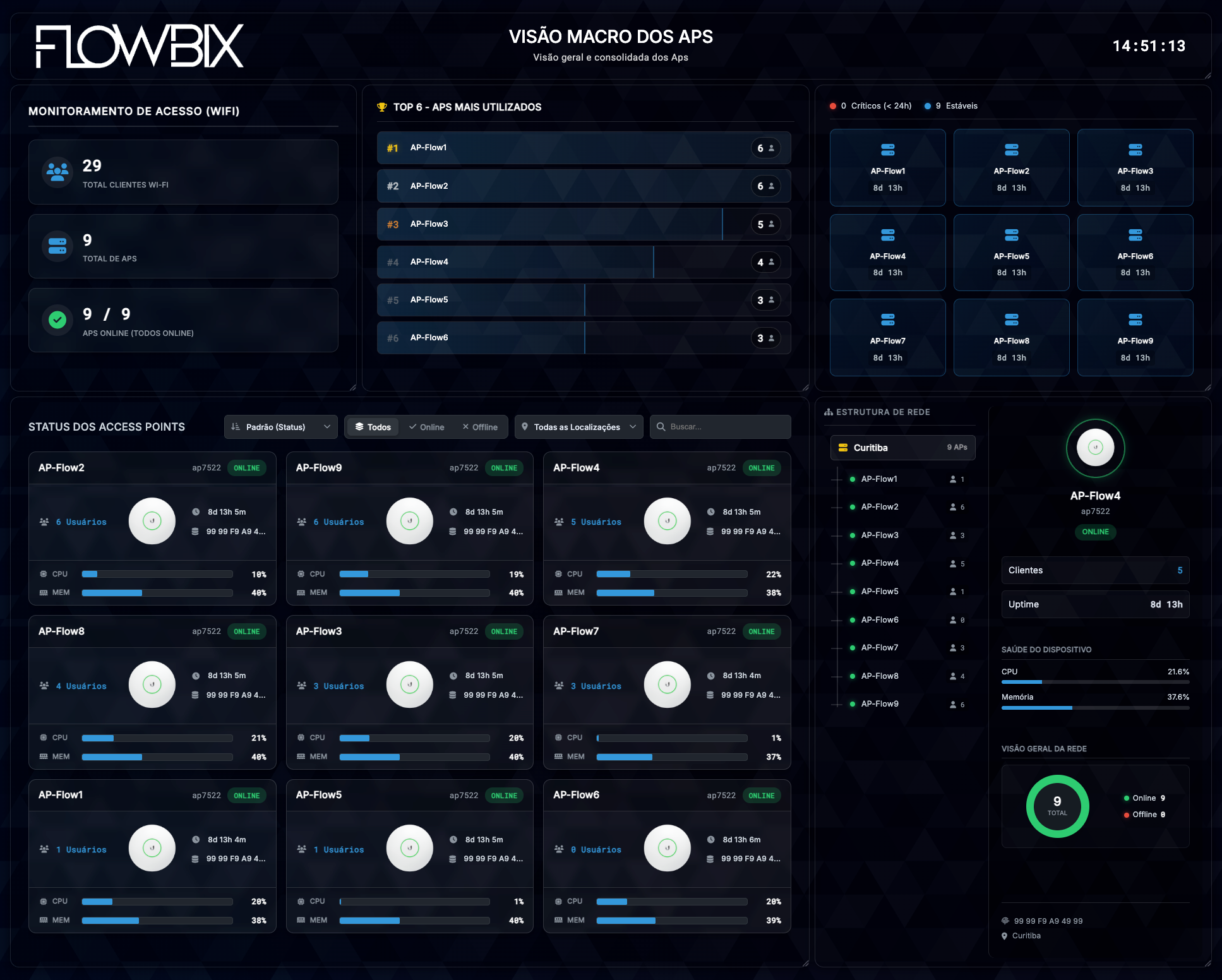
Telecom · Provedores e ISPs
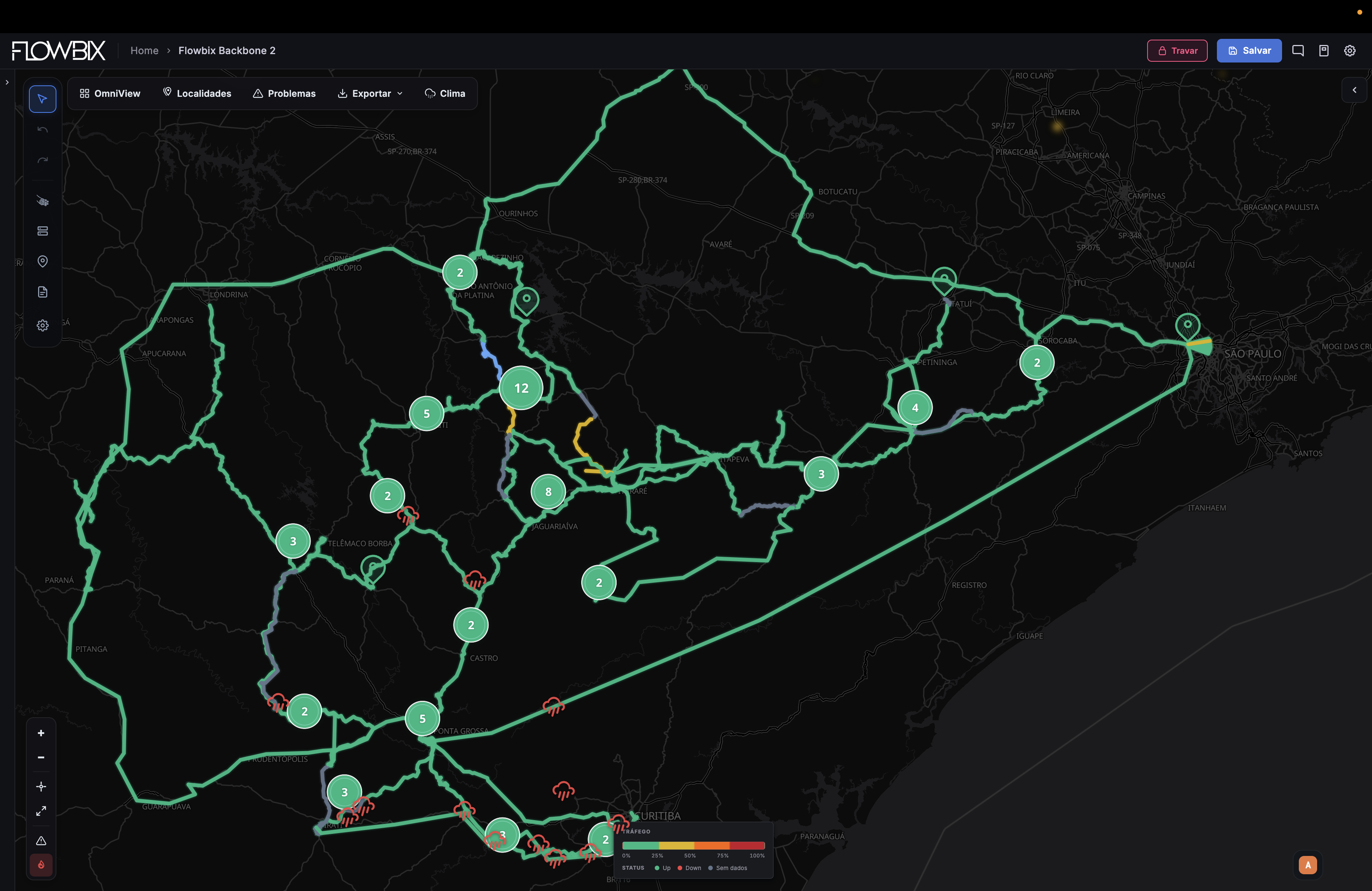
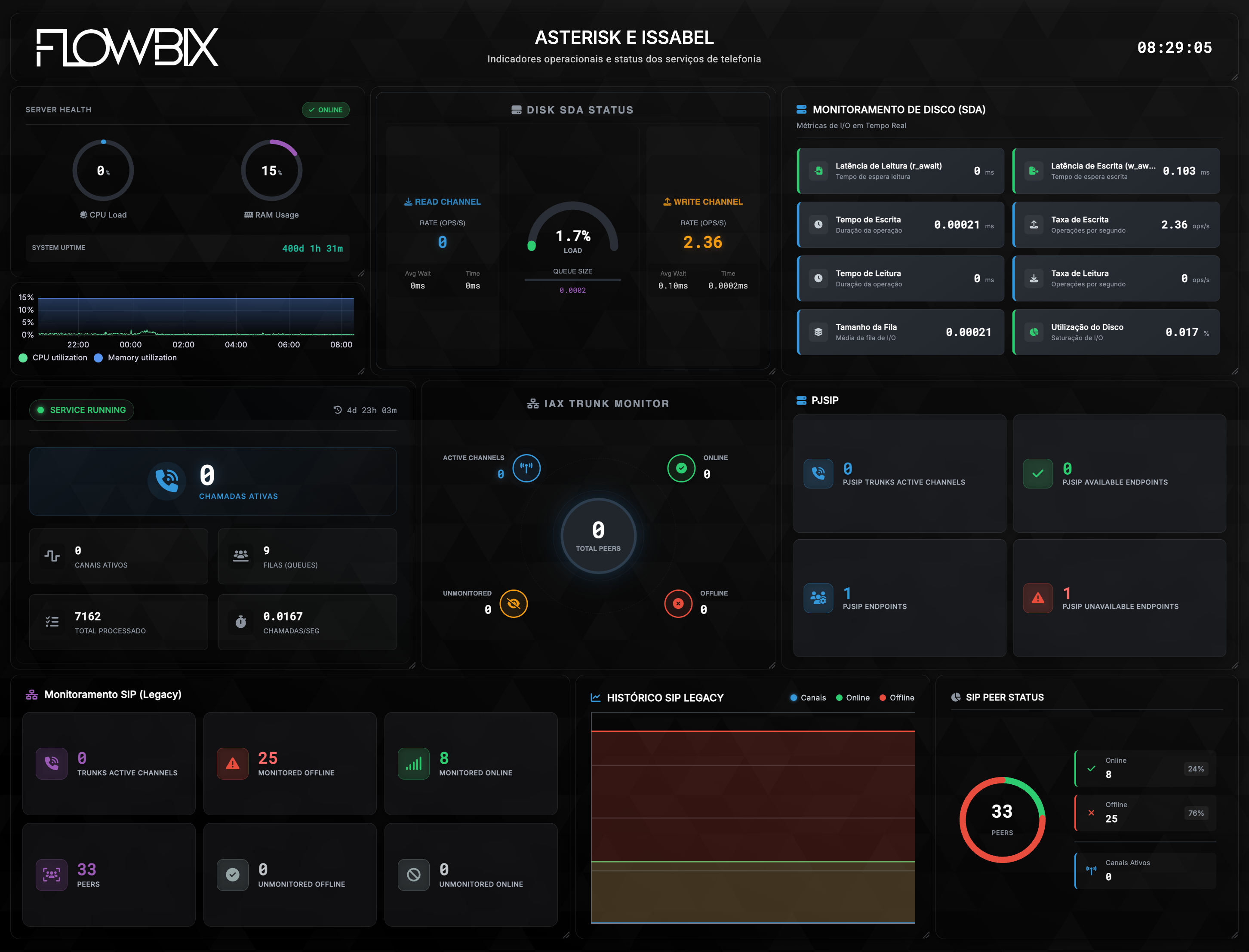
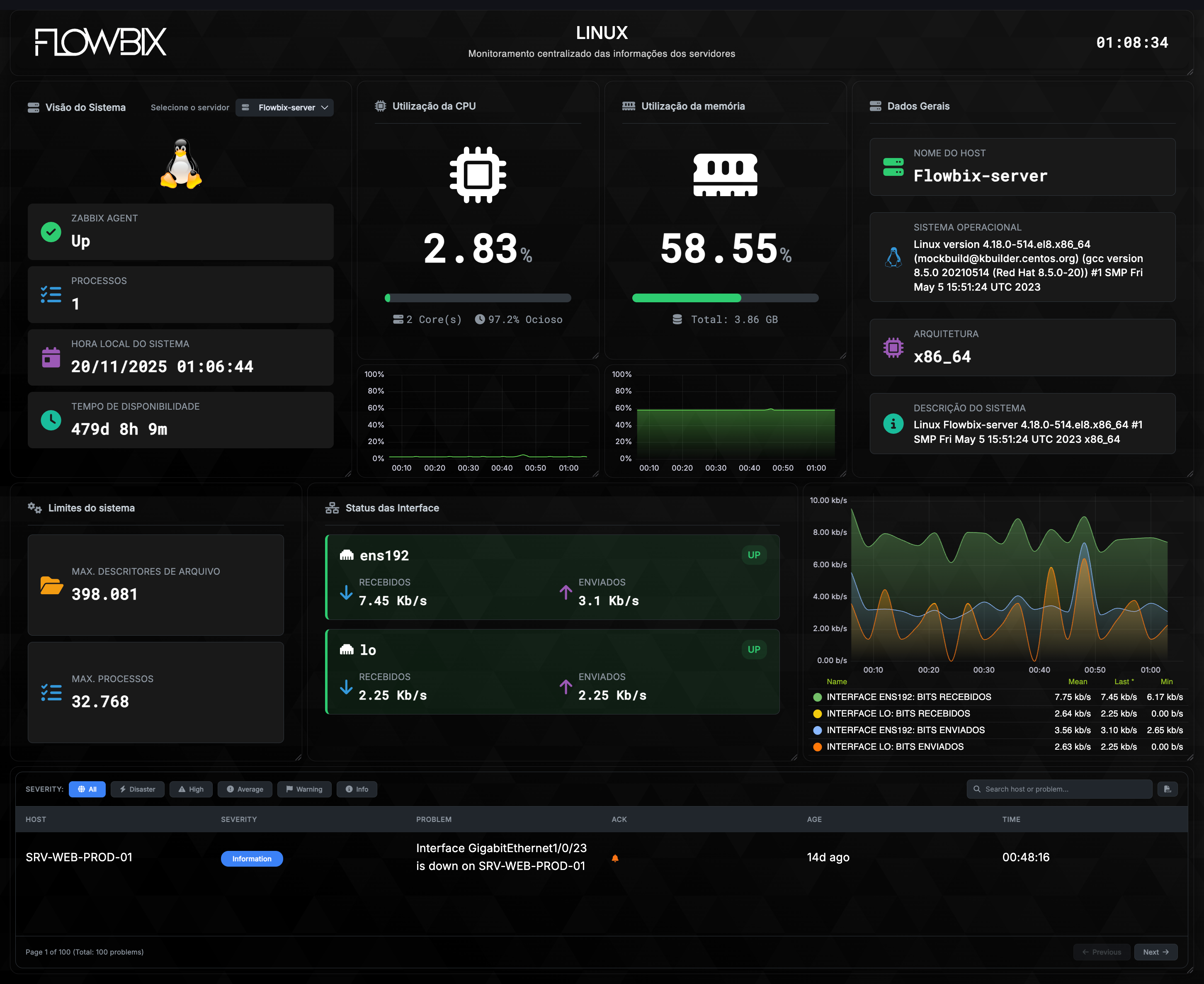
Telecom — a fundação
Backbone, FTTH, PONs, BGP, NOC e SLA. Observabilidade ponta a ponta sobre Zabbix e Grafana.
BackboneFTTHPONsBGPNOCSLA
Acessar
37 soluções
Em operação
02
Infraestrutura · Data Center
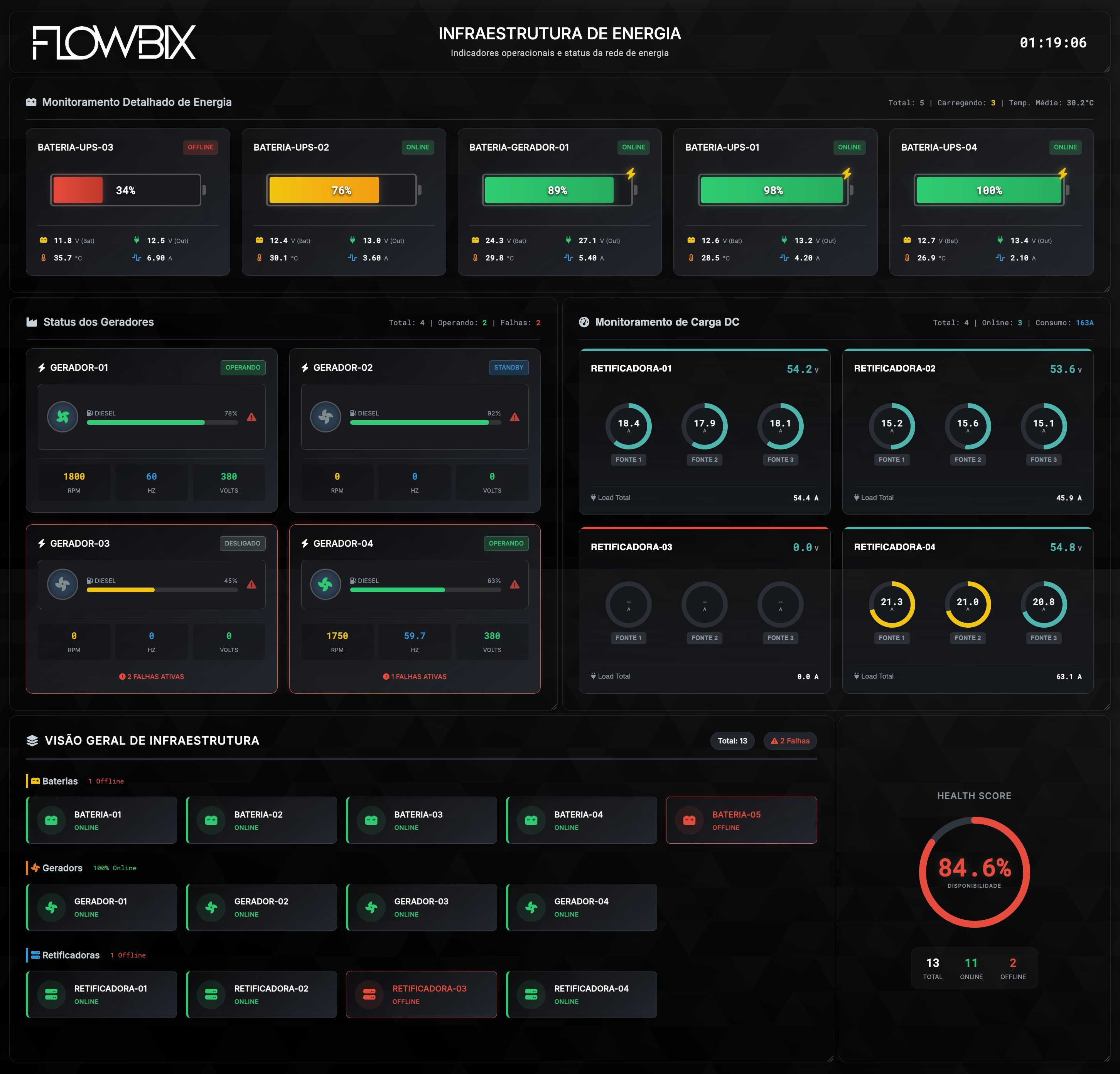
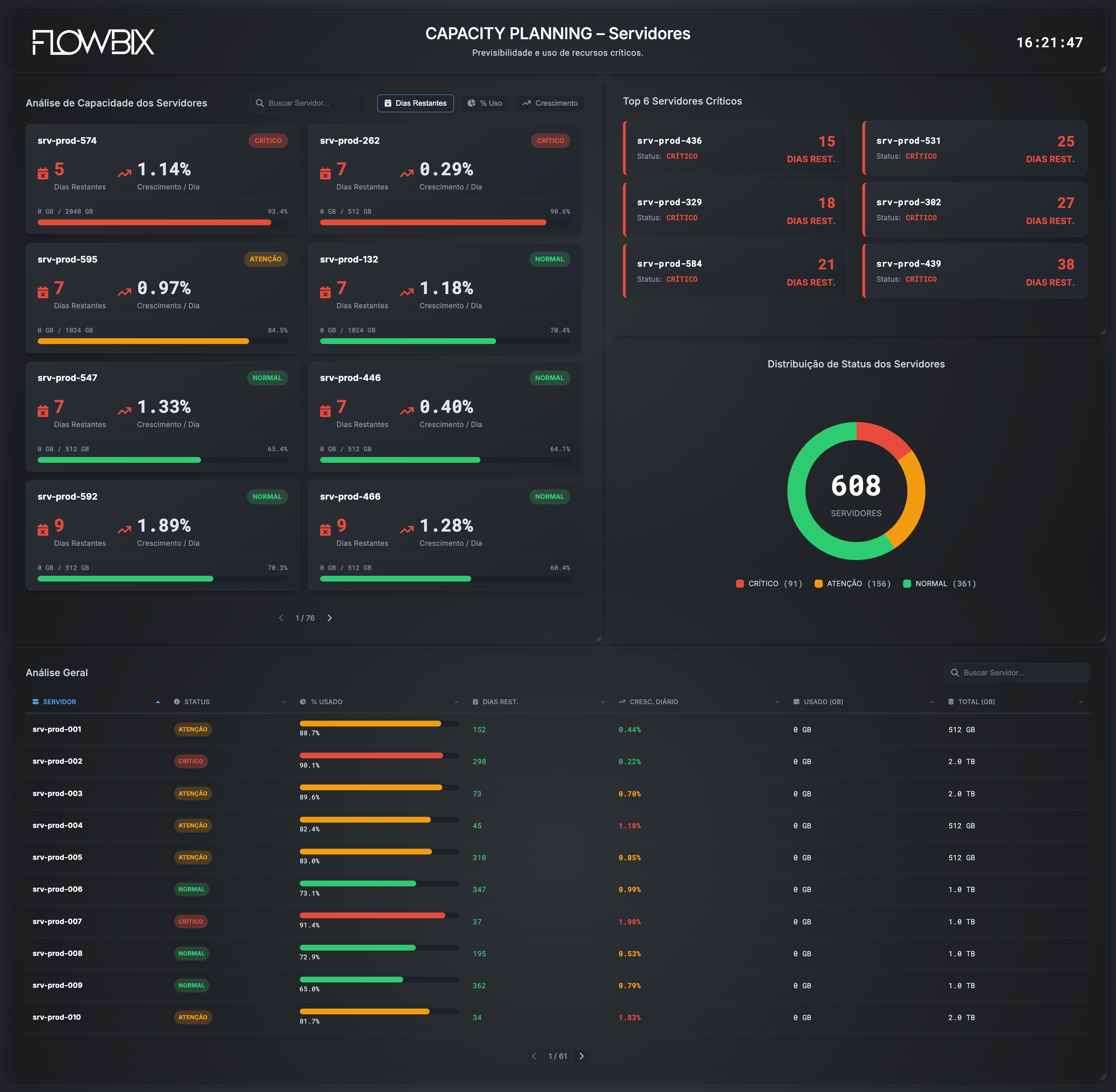
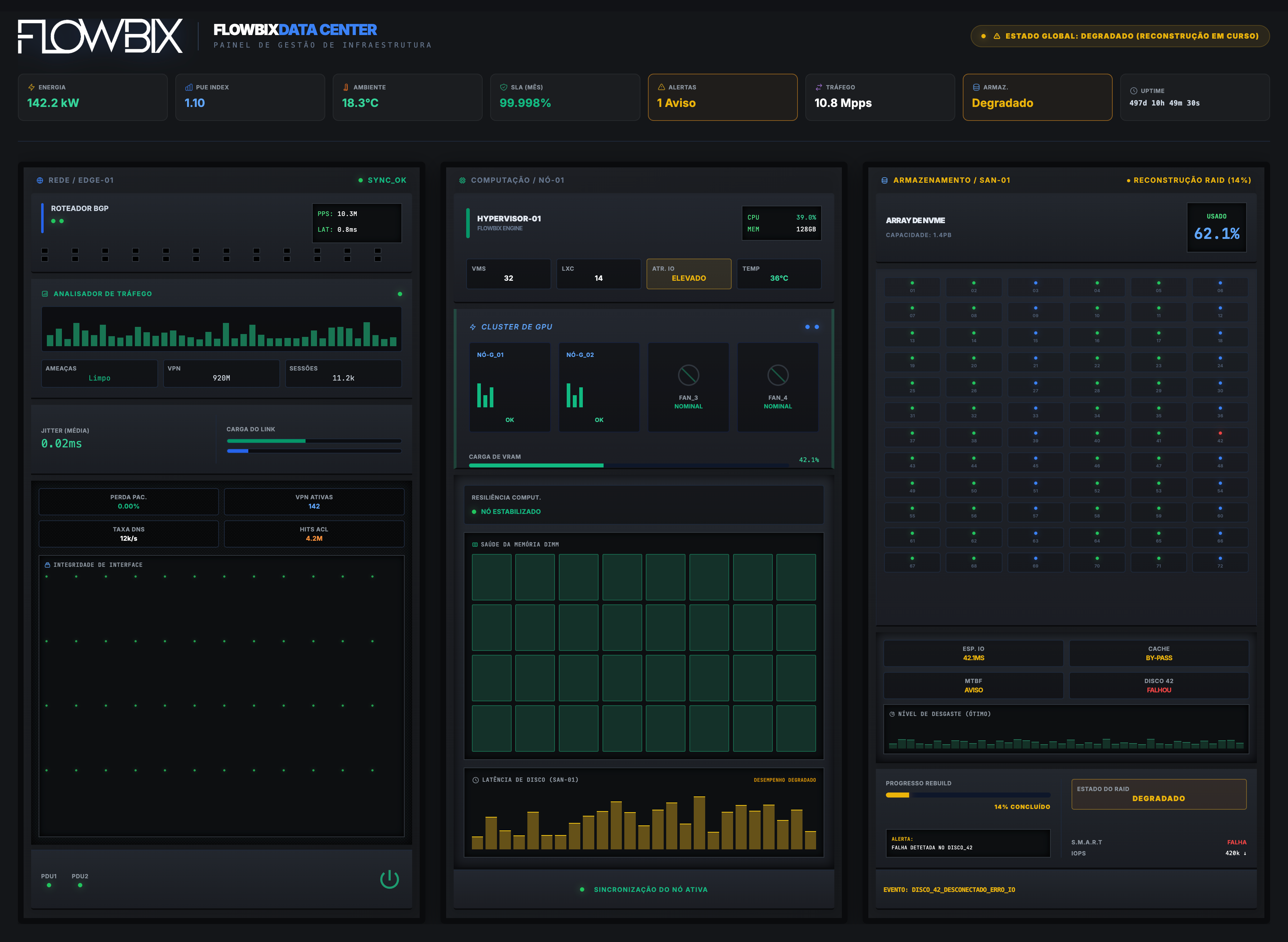
Infraestrutura — a base
Data center ao vivo. Energia, PUE, ambiente, rede, computação, GPU, armazenamento e SLA.
EnergiaPUEBGPGPUNVMeSLA
Acessar
FlowbixDATA CENTER
Em operação
04
Varejo · Operação e negócio
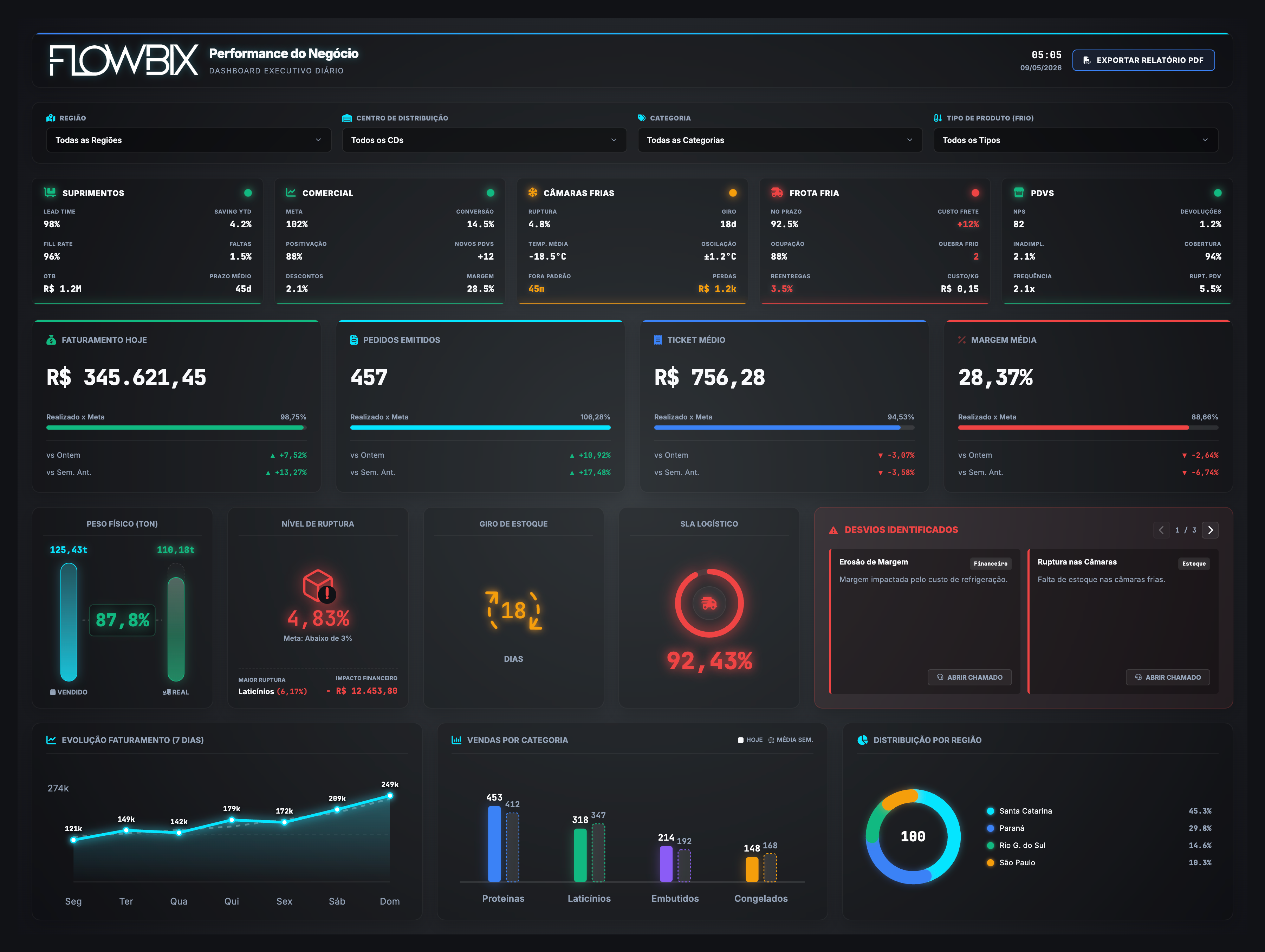
Varejo — o negócio
Oito dashboards do negócio inteiro. Performance, logística, vendas, planta, estoque, cliente e preço.
PerformanceLogísticaVendasEstoqueClientePreço
Acessar
22 soluções
Em operação
03
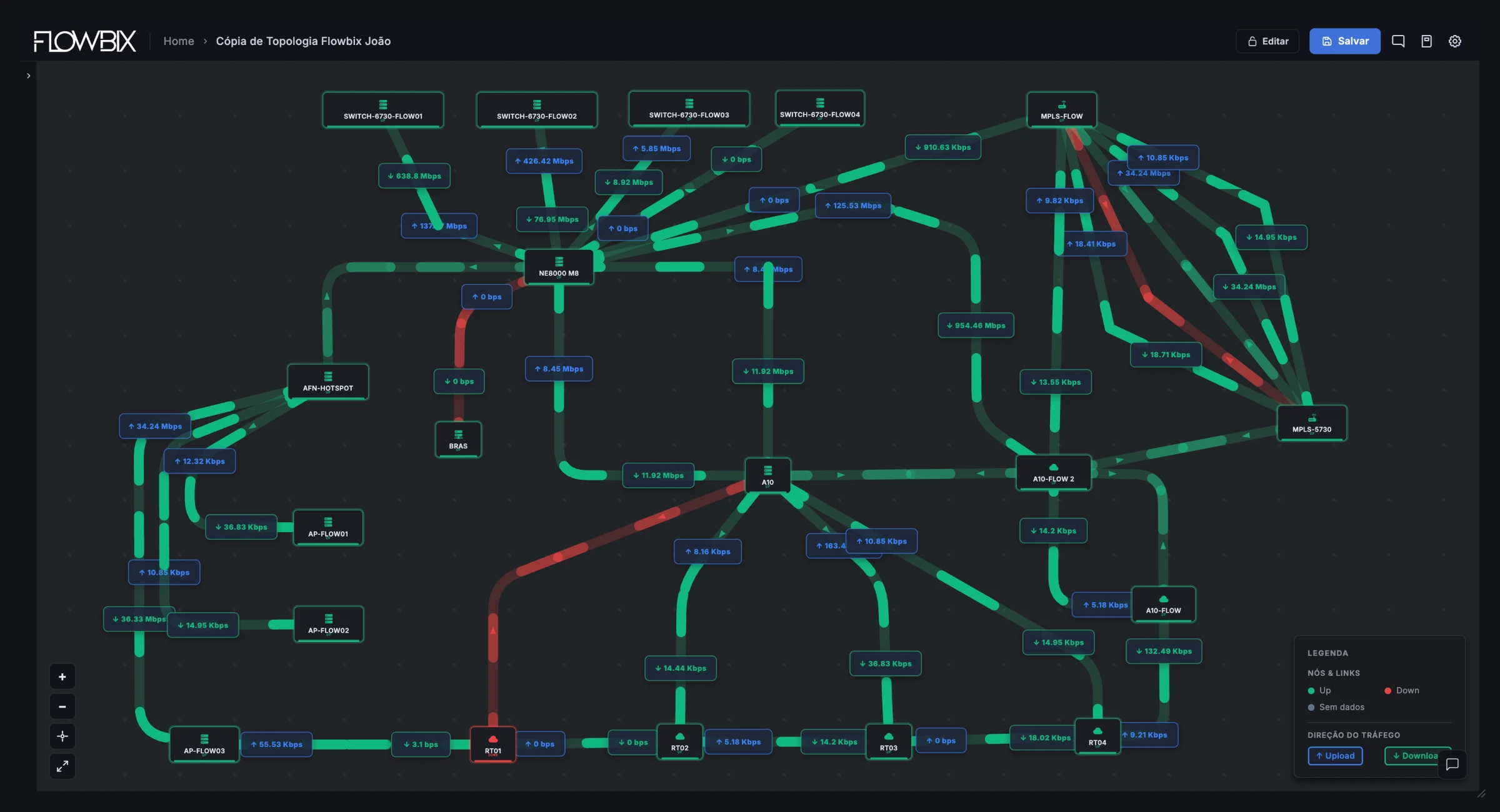
Netflow · Análise de tráfego
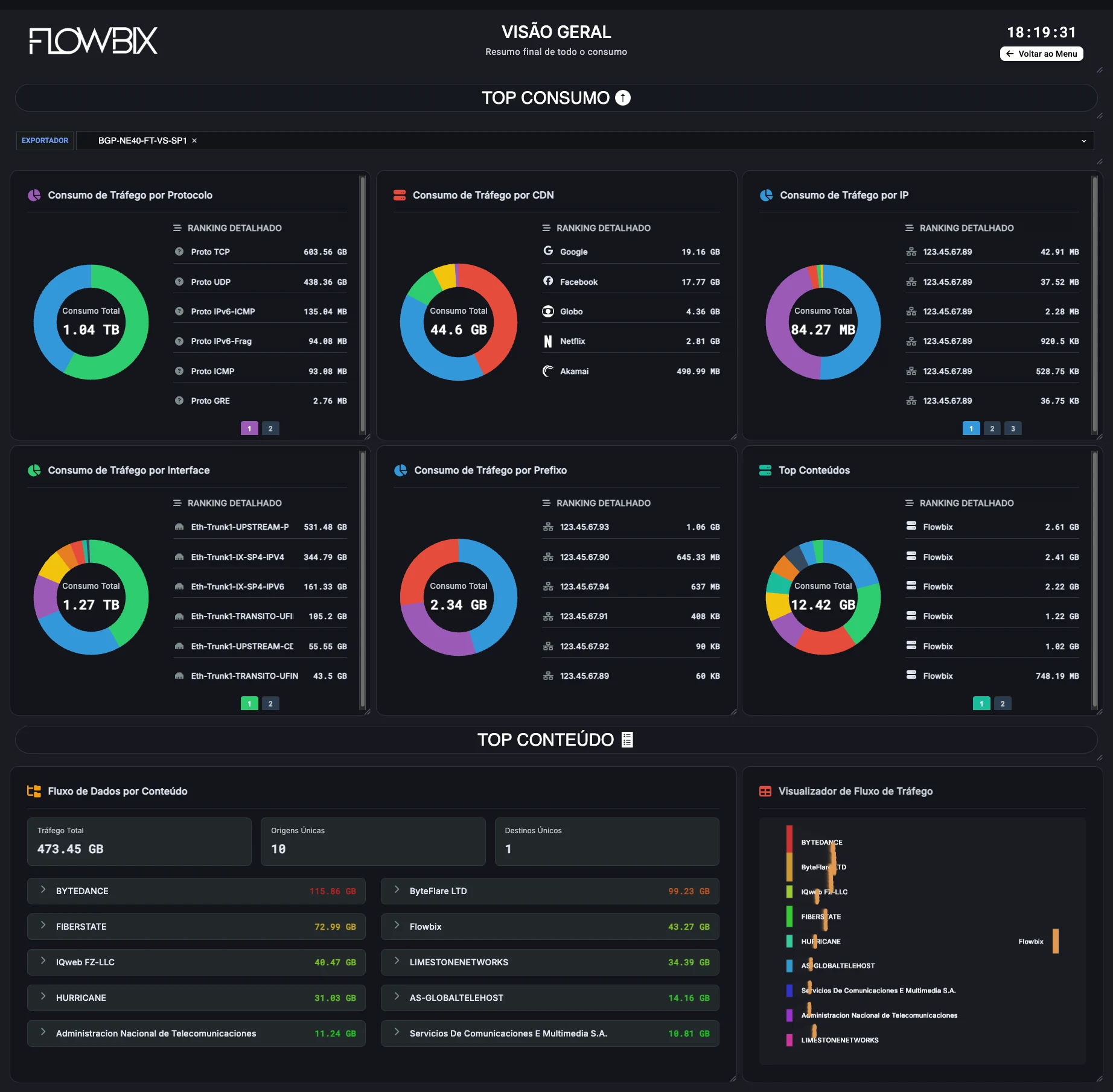
Netflow — o fluxo
Tráfego em tempo real. Composição por aplicação, top‑talkers, picos, ASNs e detecção de anomalias.
TráfegoTop‑TalkersAplicaçõesAnomaliasBGP/ASDDoS
Acessar
32 soluções
Em operação
05
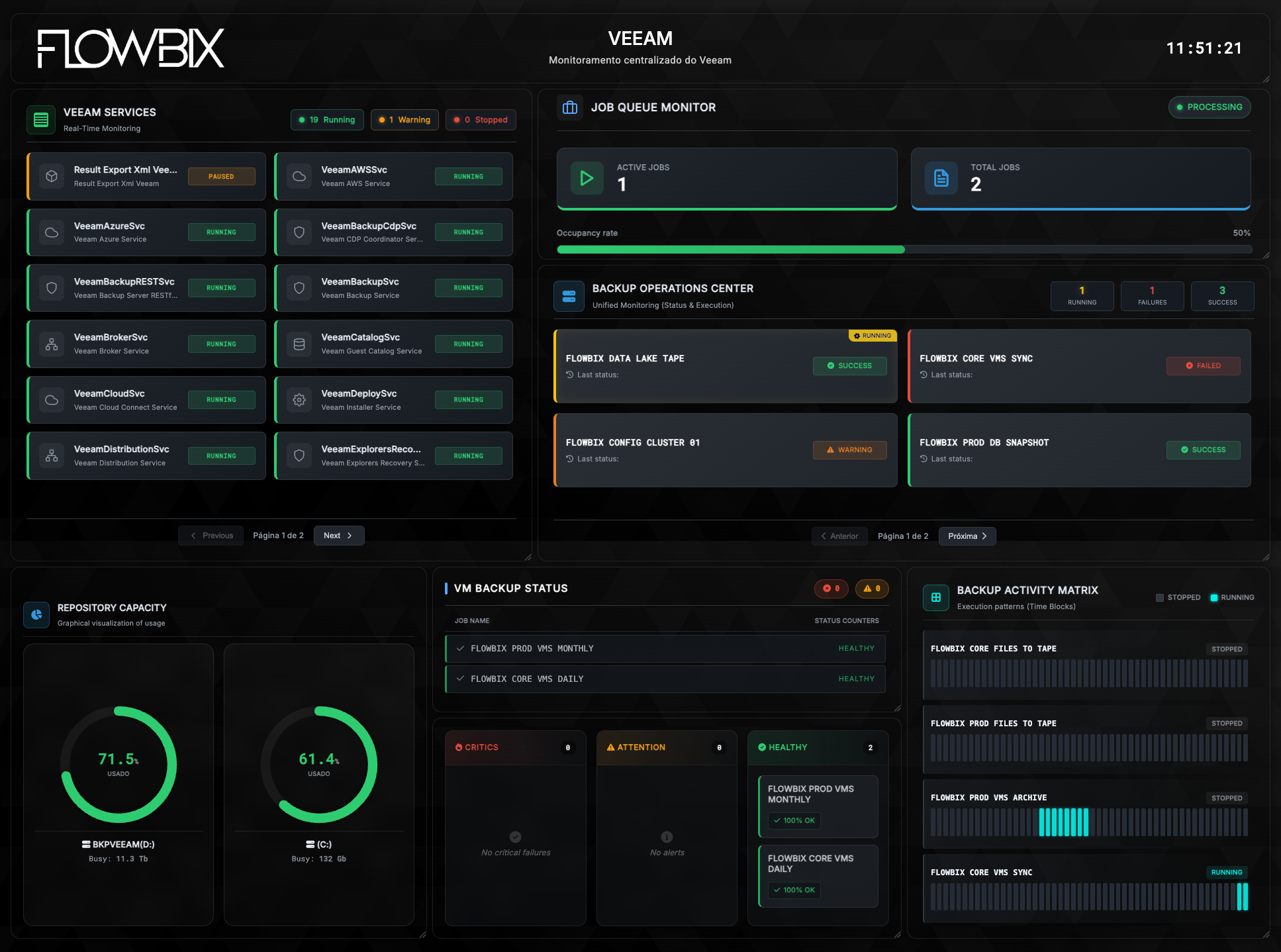
ITSM · Sistema de chamados & SLA
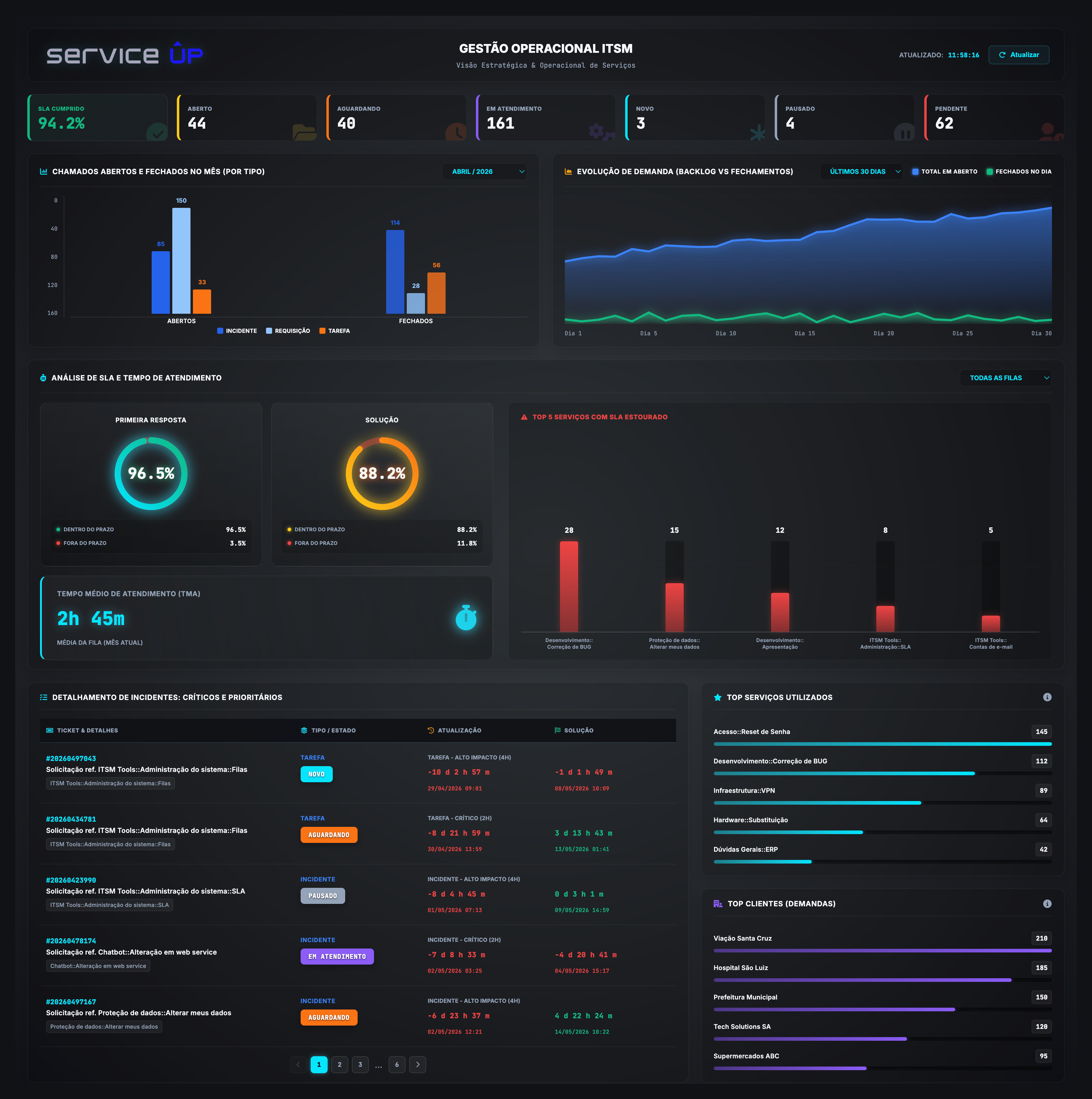
ITSM — o atendimento
Operação de chamados ao vivo. SLA, backlog, primeira resposta, solução, top serviços e clientes.
SLABacklog1ª RespostaSoluçãoTMAFilas
Acessar
service ÛP
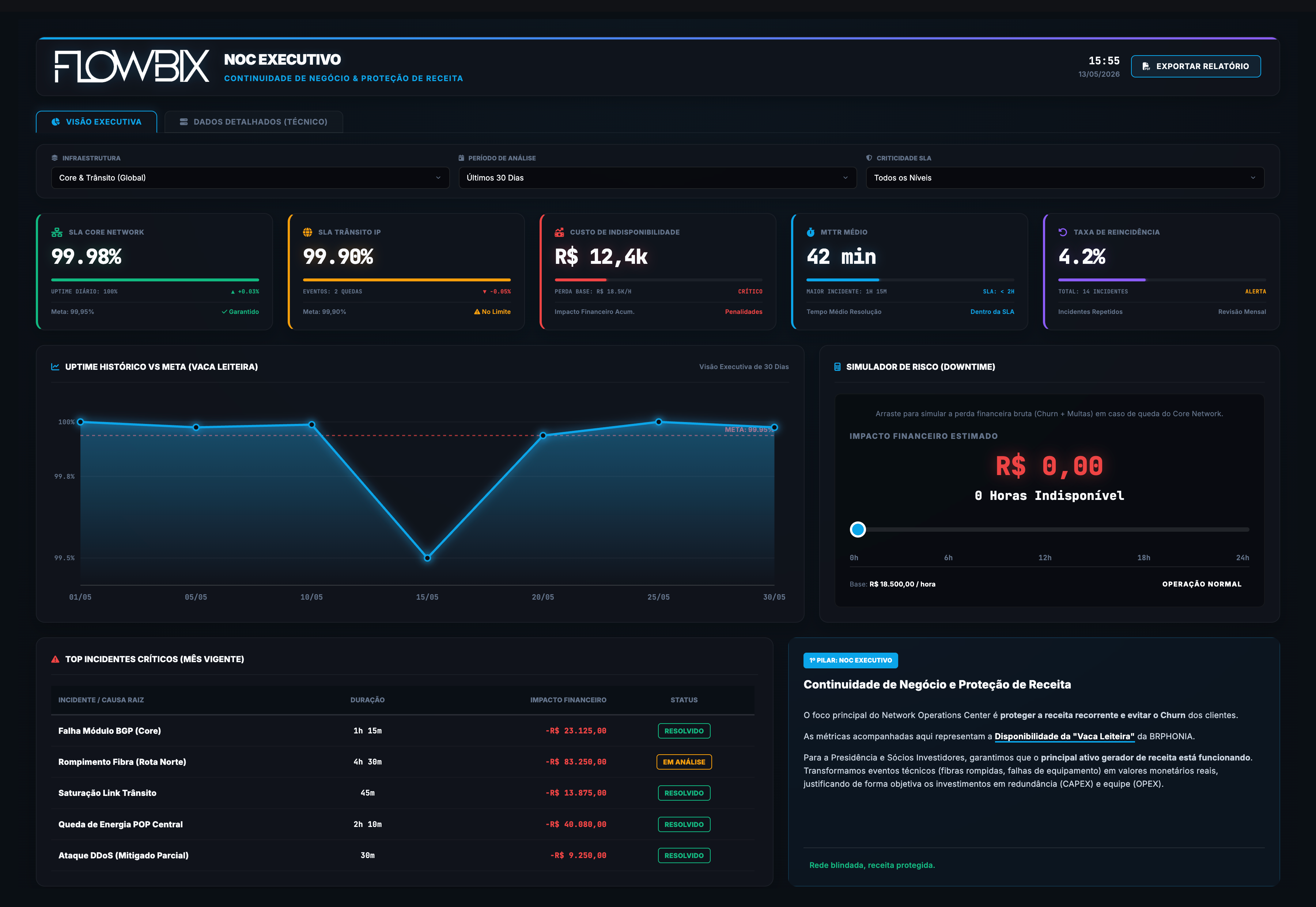
Em operação
06
Negócio · Visão Executiva
Negócio — a decisão
Cockpit executivo ao vivo. Continuidade, proteção de receita, resiliência de riscos e eficiência de capital.
SLAMTTRReceitaRiscoCAPEXSaturação
Acessar
Flowbix Executivos